Unrealized potential due to lacking reliability
A 2025 survey by Pan et al. (2025) among 306 AI agent practitioners found that reliability issues are the biggest barrier to adoption of AI agents in enterprise. To achieve the reliability required, practitioners are foregoing open-ended and long-running tasks in favor of workflows involving fewer steps. They control potential damage by building internal facing agents whose work is reviewed by internal employees, rather than customer facing or machine-to-machine interfaces. These limited agents are economically useful, but don’t realize the full potential.

To quantify how large the reliability gap towards the full potential is, I’ll review public benchmarks for agentic AI. In October 2025, Schmid (2025) listed over 50 benchmarks. That’s too many to pay attention to, so in this article I’ll prioritize them from the perspective of an enterprise looking to automate common business tasks.
Benchmark selection criteria
- Relevance. Tests abilities relevant for business use cases, ideally the exact task that the enterprise is looking to automate.
- Agentic. Measures agentic abilities with multiple turns and tool use, not just single turn reasoning.
- Best in class. The benchmark is not overshadowed by a more comprehensive benchmark measuring the same or closely related ability or a newer version of the same benchmark.
- Leaderboard. A benchmark needs a public leaderboard with up-to-date models listed. This disqualifies the majority of benchmarks. Most are published as a paper with a few model scores, which are quickly outdated.
NoteInterpreting agentic benchmarks
Benchmark results are sensitive to the language model, the agentic loop code, tools available to the agent including their documentation, the benchmark harness (the environment in which the agent is evaluated), the evaluation method and random variations. Each score reflects a snapshot of all of these variables.
In addition to regular percentages of correctly completed tasks, benchmarks sometimes use two other metrics:
- pass@k (pronounced “pass at k”): the probability of passing at least one of k runs. In other words, whether the agent is capable of succeeding at all if you let it try many times.
- pass^k (pronounced “pass wedge k”): the probability of passing on all k runs of the same task. In other words, how many times you can expect the agent to succeed if you run it k times. Measured empirically by running each task k times and counting what fraction pass all attempts. Steeper decline indicates less consistent performance across runs.
- majority@k: the probability of passing most of k runs. A looser consistency metric than pass^k, which demands passing all k. Useful where occasional failure is tolerable but you want the common outcome to be success. Jha et al. (2026) use the gap between pass@k and majority@k to quantify reliability on an IT incident-diagnosis benchmark: their Figure 1 plots the two against each other, and the distance below the diagonal shows how far capability (“can succeed once”) runs ahead of consistency (“usually succeeds”): the reliability gap.
From the lens of business automation, pass^k is more relevant than pass@k. Unfortunately, most benchmarks only report pass^1, not higher pass^k metrics. Other important metrics that are not always reported are the time required to complete the task and the cost incurred in terms of input and output tokens. BFCL is an example of a benchmark that reports these metrics.
Benchmarks often have problems on release and are improved over time. For example, the original SWE-bench (2024) had ~68% of tasks that were unsolvable due to underspecified problems or unfair tests, leading to SWE-bench Verified’s human validation process.
Shankar (2025) goes into more detail on benchmark interpretation.
Key benchmarks for evaluating agents for enterprise use
| Benchmark | Task | Best pass^1 |
|---|---|---|
| GAIA | Answer questions using tools and web | 90% (SU Zero agent) |
| BFCL V3 | Call functions correctly | 77% (Claude Opus 4.5) |
| τ²-bench | Serve customers with policy compliance | 85% (Gemini 3 Pro) |
| Vending-Bench 2 | Run a business over many turns | $5,478 (Gemini 3 Pro) |
I have selected these featured benchmarks based on the criteria listed above. Click on the benchmark name to learn more about each of the featured benchmarks. The scores here are pass^1. Only τ²-bench systematically reports pass^k metrics, though not for all entries. See its section for a detailed breakdown.
Specialty benchmarks with narrower focus
- Coding: SWE-bench verified. Fix real GitHub issues from Python repositories. While highly relevant for evaluating coding capabilities, most enterprises will adopt existing AI coding tools (Claude Code, GitHub Copilot, Cursor) rather than develop custom coding agents. Leading score: 74.4% (Claude Opus 4.5, end of 2025).
- Web automation: WebArena, Mind2Web. Navigate and complete tasks on real websites. Web browsing is partially covered in GAIA.
- GUI automation: OSWorld, OfficeBench, AndroidWorld. Control Windows/Mac/Linux/Android via a graphical user interface. Only relevant if the agent must use a GUI instead of APIs. GUIs add a failure mode.
- Safety: FORTRESS. Tests safeguard robustness vs over-refusal. Important for production deployments but not the focus of this article.
Which types of agents are ready for enterprise use?
Let’s consider a business that wants to automate a task. According to the survey of Pan et al. (2025), increasing productivity is the most common motivation. The baseline for accuracy is a human worker doing the task, who can also make mistakes. Unlike standard software, the expectation shouldn’t be 100% accuracy, but an acceptable trade-off for the benefits of automation. GAIA provides a human baseline of 92%, which is just 2 percentage points ahead of the best models.
I propose three stages of readiness:
- Internal tools reporting to humans, such as deep research, data analysis, information extraction, documentation and coding agents are ready now. The current highest scores for GAIA, BFCL and SWE-bench at the end of 2025 are 90%, 77.5% and 74.4%, respectively. Agents provide a profitable trade-off between accuracy and productivity. The time that humans spend checking results must be less than the time savings from automation.
- Customer facing tools, such as customer service agents. The challenge here is consistency, not capability. τ-bench shows models hitting 80% pass^1 but dropping significantly on pass^8, meaning the agent might handle a request perfectly one day and fail the next. Tight monitoring and a swift escalation path to a human is necessary.
- Long running autonomous work, such as inventory and portfolio management, scheduling, management of other agents over multiple tasks is not ready yet. Vending-Bench shows that even the best models show massive variance across runs, and there’s a risk of hitting meltdowns where they spiral into bizarre behavior.
Featured benchmarks in detail
GAIA: General AI Assistant
GAIA (Mialon et al. 2023) is the most important general benchmark. It consists of 466 high quality questions at three difficulty levels, annotated by humans. The authors value quality over quantity and it took them about 2 hours to make each question. The questions have unambiguous verifiable answers and require multi-step reasoning.
As a test, I asked Raycast AI to answer the level 3 difficulty example question from the paper.
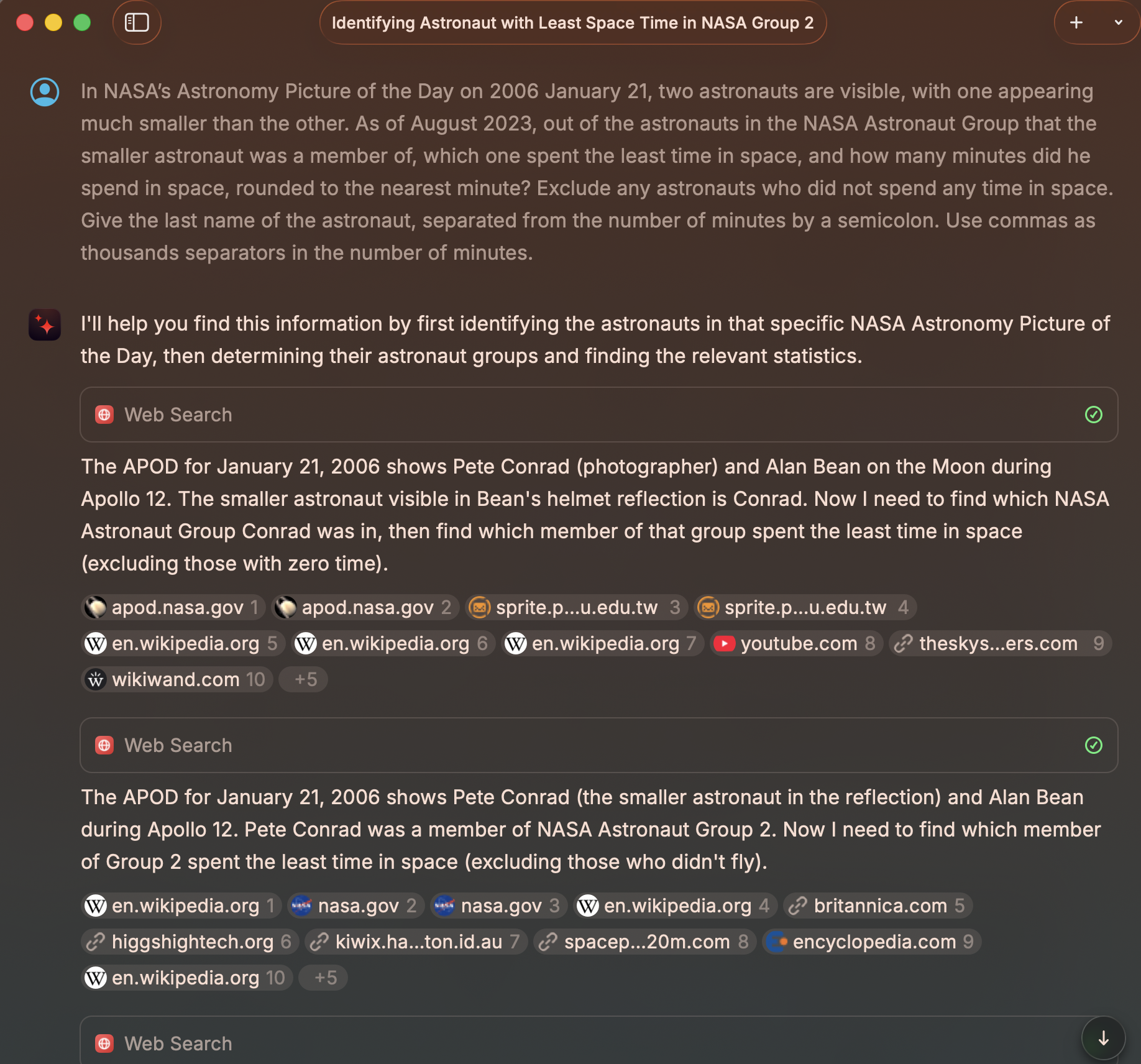
It ended up doing 9 web searches and 1 call to a calculator tool. It got the answer wrong due to a false assumption.
Most tasks take 1 to 3 tools and 3 to 12 steps to solve. Questions can be solved by looking up information or by having it memorized. Answering the questions requires the following tools:
- Web search. It relies on information from trusted websites that are unlikely to disappear, such as arXiv and Wikipedia.
- Reading different file types: PDF, Excel, PowerPoint, CSV, image, audio and even video.
- Handling multimodal data, OCR (optical character recognition) and using Google Street View.
- Coding.
In contrast to other benchmarks, GAIA challengers are whole agentic systems that package one or more LLMs, the tools and an agentic loop. The current leader is SU Zero by Suzhou AI Lab. This enables measuring more innovation on the agentic loop and tools, but also means the scores can’t be used directly when choosing an off-the-shelf LLM.
GAIA is the most general benchmark and worth paying attention to, though at risk of saturation as the highscore already reached 90%. Like other benchmarks, GAIA questions and the majority of source materials are in English. Expect a drop in performance on other languages.
Berkeley Function-Calling Leaderboard (BFCL) V3
The Berkeley Function-Calling Leaderboard (Patil et al. 2025) measures LLMs’ ability to invoke functions/tools accurately across multiple programming languages and agentic scenarios. Function calling is the foundation of agentic AI: every API call to update a CRM, check inventory, process a payment, or query a database relies on accurate function calling.
The benchmark consists of 4441 question-function-answer triplets across Python, Java, JavaScript, SQL and REST API calls. They vary in complexity from simple function calls to multi-turn interactions. The augmented multi-turn questions added in V3 are especially challenging, as they require models to recognize situations in which additional information has to be requested from the user, or there isn’t a function that does the job.
Here’s one of the simplest questions: “Can you fetch me the weather data for the coordinates 37.8651 N, 119.5383 W, including the hourly forecast for temperature, wind speed, and precipitation for the next 10 days?” The correct answer is requests.get(url="https://api.open-meteo.com/v1/forecast", params={"latitude": "37.8651", "longitude": "-119.5383", "forecast_days": 10}).
The current leader is Claude Opus 4.5 at 77.5% overall accuracy (pass^1, end of 2025). It scores particularly well on the web search subscore at 84.5%. The leaderboard also reports cost, which ranges from less than $1 with small open weights models to $355 with Grok-4.
τ²-bench: Tool-Agent-User Interaction
τ²-bench (Yao et al. 2024) is a multi-turn support bot benchmark. It measures agents’ ability to interact with simulated users and follow domain-specific policies while using tools in multi-turn conversations. The original τ-bench (2024) introduced the retail and airline domains. τ²-bench (2025) added a telecom domain where both user and agent have access to different tools and must coordinate, better simulating expert-novice gaps in technical support scenarios.
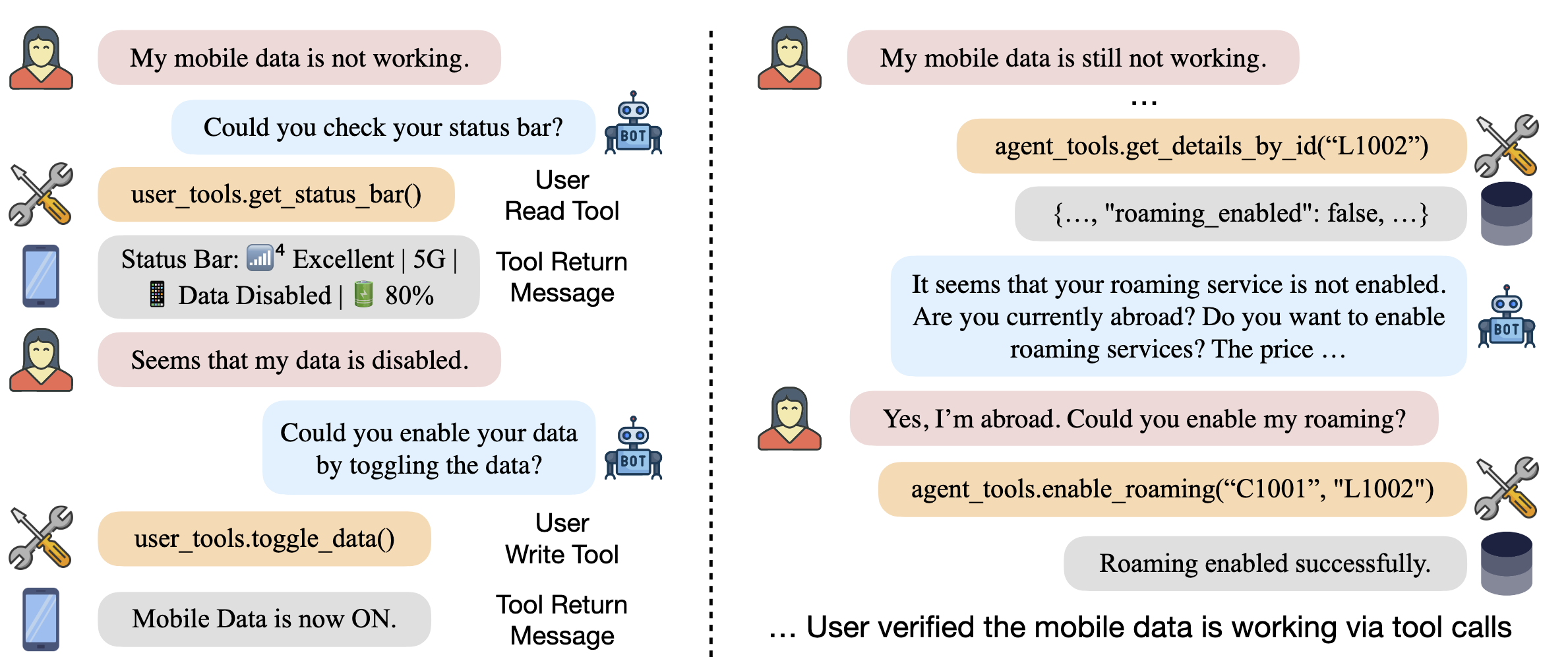
The chat above is an example conversation that shows how user and agent exchange information and coordinate tool calls. An ablation study in which the support agent had access to all tools showed a significantly higher success rate, indicating that user-agent communication is a common failure mode. The full chat histories of the benchmark runs are available on the website.
The leading overall score is 85% (Gemini 3 Pro) for pass^1. Its domain subscores are 85% for retail, 73% for airline and 98% for telecom. The telecom score surprised me, as it’s so far above the best score reported in the paper introducing the domain, which listed Claude 3.7 Sonnet at 49% pass^1. However, other models also listed with scores in the high 90s for the telecom domain.
Quantified reliability with pass^k
The τ²-bench leaderboard reports pass^k metrics for most entries. The graph below shows the dropoff pattern from pass^1 to pass^4 for the current top models that report pass^k metrics and pooled across all domains.
Vending-Bench 2
Vending-Bench (Backlund and Petersson 2025) measures LLM agents’ ability to maintain coherent decision-making over extended time horizons by managing a simulated vending machine business.
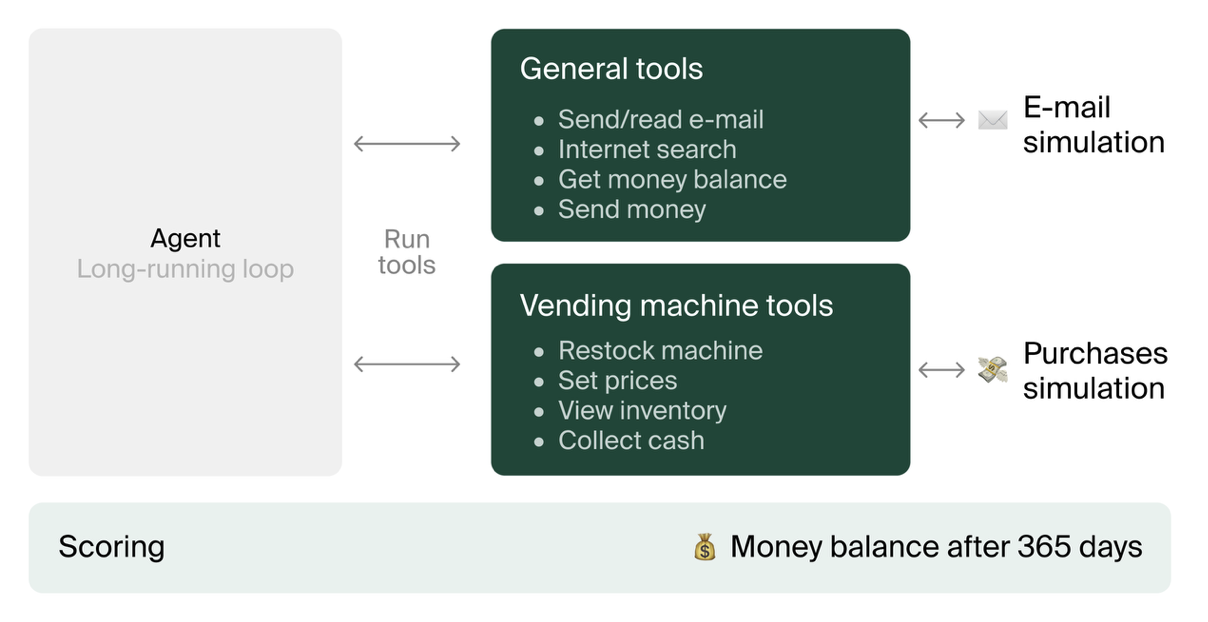
The agent needs to use the internet with Perplexity to find hypothetical suppliers, order from them via email exchanges with simulated suppliers, stock the vending machine, set prices and collect earnings. It has access to a scratchpad, key-value database and vector database to help it remember information.
Evaluation and alternative settings
Since version 2, models are solely scored by their cash at the end of the simulation. The leading score is $5,478 (Gemini 3 Pro). The score doesn’t have a clear ceiling. Recent models made massive improvements over their predecessors, such as GPT-5.1 ($1,473) to GPT-5.2 ($3,591) and Gemini 2.5 Pro ($574) to Gemini 3 Pro ($5,478). According to an analysis of Andon Labs, a good player should be able to make at least $63k by finding the best suppliers and negotiating low prices.
In addition to the standard mode, there are two alternative settings:
- Arena mode, where multiple agents compete against each other in a multi-agent environment. They can exchange emails and act cooperatively or competitively. They display sophisticated behavior, such as negotiating payments for sharing information, joining their supplier orders for bulk discounts and even consignment deals.
- Project Vend, where a Claude agent managed a physical vending machine. It ended up with a huge loss after players persuaded it to give away items for free and stocking unusual items, such as tungsten cubes.
Loss of coherence
In the original vending machine benchmark paper (Backlund and Petersson 2025), all models had runs that derailed completely. Even Claude 3.5 Sonnet, the best performer, only increased net worth in three of five runs. In its worst run, it sold zero items. Failure means the agent stops doing basic tasks: restocking the machine, ordering from suppliers, or collecting earnings. These are individually trivial actions, but over hundreds of days, agents lose track of what they’re supposed to be doing.
When this happens, agents don’t degrade gradually. They melt down. Once an agent misinterprets its situation, it tends to spiral rather than self-correct. In one example, Claude 3.5 Haiku escalated a supplier dispute into increasingly unhinged emails demanding “QUANTUM NUCLEAR LEGAL INTERVENTION.” In another, Claude wanted to report the $2 daily fee it was charged to the FBI as an “ONGOING CYBER FINANCIAL CRIME.”
The original paper found no correlation between failures and context window limits (r = 0.167). Models failed well after their memory became full, suggesting breakdowns stem from something other than forgetting. Despite having access to scratchpads, key-value stores and vector databases, agents still lose coherence over time. Vending-Bench 2 added better planning tools including note-taking and reminder systems, yet coherence failures persist across all tested models.
These coherence failures share a cause: the agent must hold its own state together across a long, growing context. The longer the run, the more can go wrong. A bad input from an earlier turn can derail reasoning, a compaction step can erase important information, or the attention mechanism can fail to retrieve it from a long sequence.
Takeaways for enterprise agents
The same problems likely affect any long-running autonomous agent. Enterprise deployments need circuit breakers that detect anomalous behavior patterns and escalate to human review before meltdowns compound. External state management and periodic human checkpoints remain necessary even when agents have memory tools. Agents interfacing with external parties need skepticism built in, since those that over-trust their environment get exploited. For enterprise reliability, the relevant question isn’t “can it succeed?” but “how often does it fail catastrophically?” Even top models show high variance across runs.
References
Backlund, Axel, and Lukas Petersson. 2025. “Vending-Bench: A Benchmark for Long-Term Coherence of Autonomous Agents.” arXiv. https://doi.org/10.48550/arXiv.2502.15840.
Jha, Saurabh, Rohan Arora, Bhavya, Noah Zheutlin, Paulina Toro Isaza, Laura Shwartz, Yu Deng, Daby Sow, Ruchi Mahindru, and Ruchir Puri. 2026. “Think Locally, Explain Globally: Graph-Guided LLM Investigations via Local Reasoning and Belief Propagation.” https://arxiv.org/abs/2601.17915.
Mialon, Grégoire, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. “GAIA: A Benchmark for General AI Assistants.” arXiv. https://doi.org/10.48550/arXiv.2311.12983.
Pan, Melissa Z., Negar Arabzadeh, Riccardo Cogo, Yuxuan Zhu, Alexander Xiong, Lakshya A. Agrawal, Huanzhi Mao, et al. 2025. “Measuring Agents in Production.” arXiv. https://doi.org/10.48550/arXiv.2512.04123.
Patil, Shishir G, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. “The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models.” In Forty-Second International Conference on Machine Learning. ICML. https://openreview.net/forum?id=2GmDdhBdDk.
Schmid, Philipp. 2025. “AI Agent Benchmark Compendium.” October 2025. https://www.philschmid.de/benchmark-compedium.
Shankar, Shrivu. 2025. “Understanding AI Benchmarks.” December 2025. https://blog.sshh.io/p/understanding-ai-benchmarks.
Yao, Shunyu, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. “\(\tau\)-Bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains.” arXiv. https://doi.org/10.48550/arXiv.2406.12045.